JSON Column to multiple columns
Consider you have situation with incoming raw data got a json column, and you need to transform each key separate column for further analysis. Here we will learn
- How to read a json column using PySpark?
- How to have create the schema for JSON Column?
- How to transform Key as column name in dataframe from key value ?
Source Code
from pyspark.sql.types import *
from pyspark.sql.types import MapType,StringType,IntegerType
data = [
(1,{"city":"Baltimore","zip_code":21201,"county":"Baltimore City"},"USA"),
(2,{"city":"East Case","zip_code":21202,"county":"Baltimore City"},"USA"),
(3,{"city":"Ruxton","zip_code":21204,"county":"Baltimore County"},"USA"),
(4,{"city":"Orchard Beach","county":"Anne Arundel County"},"USA"),
(5,{"city":"Arbutus","zip_code":21227,"county":"Baltimore County"},"USA"),
]
schema = StructType([
StructField("si_no",IntegerType(),True),
StructField("city_info",MapType(StringType(),StringType(),True)),
StructField("country",StringType(),True),
])
df = spark.createDataFrame(data,schema)
df.show(20,False)
df.printSchema()
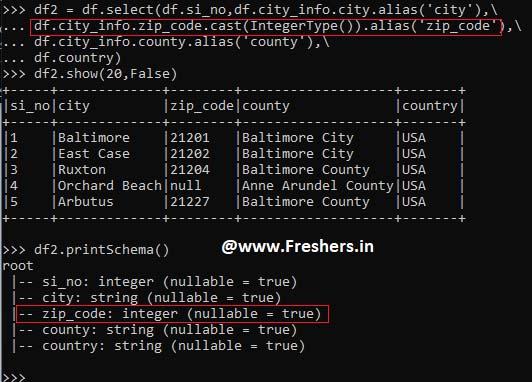
df2 = df.select(df.si_no,df.city_info.city.alias('city'),\
df.city_info.zip_code.cast(IntegerType()).alias('zip_code'),\
df.city_info.county.alias('county'),\
df.country)
df2.show(20,False)
df2.printSchema()
Reference
- Spark Examples
- PySpark Blogs
- Bigdata Blogs
- Spark Interview Questions
- Official Page
- How to parses a column containing a JSON string using PySpark(from_json)
Execution Result